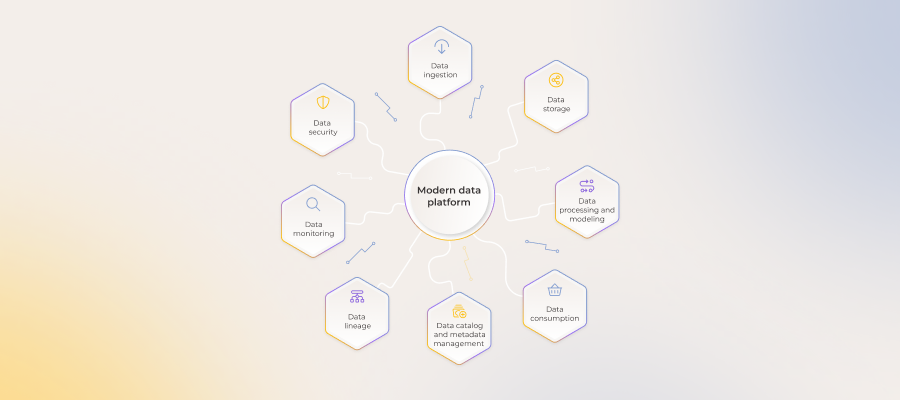
The world of data is filled with promising quotes, such as “information is the oil of the 21st century” or “data is becoming the new raw material of business.” However, the value ingrained in data only becomes vivid when analytics solutions come into play.
Before analytics can start, data needs to be prepared. This stage is a foundation for efficient and effective analysis. And this is where data infrastructure enters the battlefield.
Consisting of data assets and processes about how to manage these assets, data infrastructure plays a significant role in transforming data into usable information and paves the way for it to turn into insights.
In this article, we navigate you through the practices that ensure your data infrastructure supports your analytics needs so you save your valuable time and resources.
Break down two significant barriers to your data analysis with a robust data infrastructure
Perhaps, in a unicorn and rainbow-like utopia, data is perfect by default. However, in real life, it’s not like that at all. There are a couple of things that can go wrong even at the very first stages of constructing a data infrastructure, these include:
- Data accessibility
- Amount of data
The second occurs when a company scales up, but the first one is relevant for companies with any scope of data, and crucial to ensuring effective data analytics processes.
Data accessibility
It doesn’t matter how clean and organized your information is if only the engineers that currently work on the product can retrieve it. In this case, reports tend to take weeks. According to Broadcom’s research on the state of Big Data Infrastructure, over half of respondents have already implemented Big Data projects and 29% are planning to start implementing them.
When you don’t have a business intelligence (BI) platform in place, the interaction with the data goes like this: your engineers extract the information required from a data lake or a data warehouse, or from somewhere else, and pass the data to analysts. Conversely, with mature BI solutions, this stage is automatized, making it easier to get the data you need when you need it.
That means, if your goal is a data-driven company, you need to build an infrastructure where everyone in the company has access to a particular data network and can analyze it.
How do you ensure data readiness? You need a well-thought-out data strategy and a clear understanding of how this data will be handled. Security requirements and security policies should always come first during the project and the implementation phase of the data strategy.
Amount of data
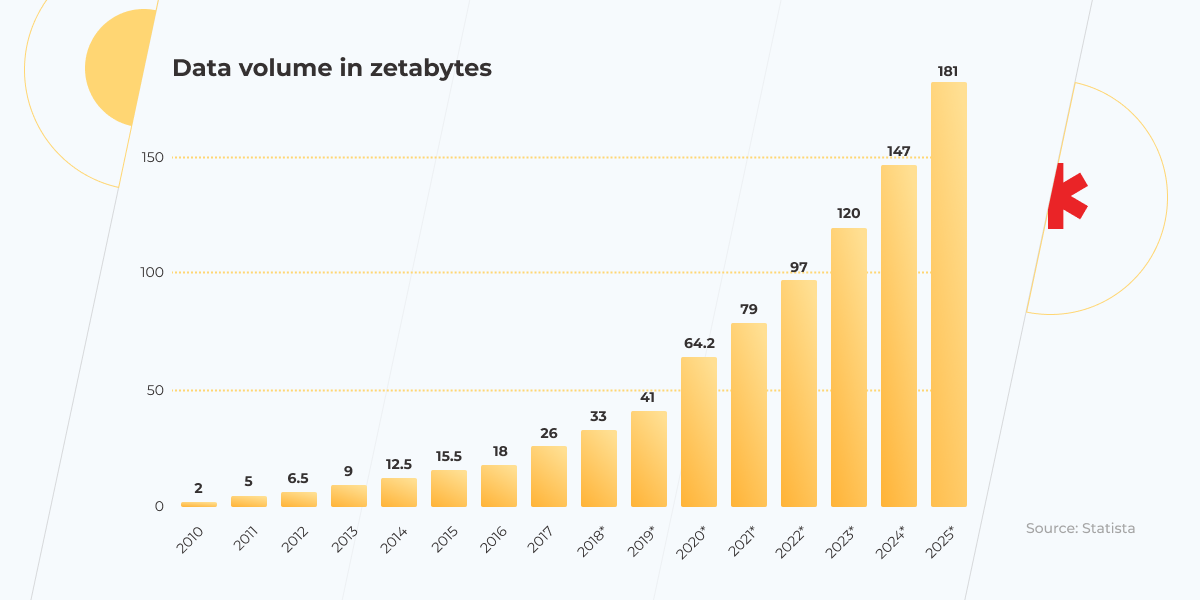
The total amount of data created in 2020 reached 64.2 zettabytes. In 2015 it was only 15.5 zettabytes. The data volume growth during the last year is mind-boggling and has only accelerated due to the pandemic, as more people than ever before have started working and studying from home. This situation became a challenge for data engineers, who were expected to build a new infrastructure to handle such a huge amount of data and get ready for exponential growth in the future in such a short space of time.
The more information you have, the more complex the architecture of the serving infrastructure will be. Data engineers need to seamlessly combine two tasks: rebuild existing data infrastructure and try not to become buried under the ever-increasing data flow.
The amount of data will naturally grow over time — that’s a fact! According to Statista, by 2025, data creation all over the world is expected to increase threefold (more than 180 zettabytes). Without implementing a proper data infrastructure in your organization, it will be troublesome to grow and stay competitive among other companies. So the best time to start preparing your data infrastructure is now.
Five must-do tips for building a robust data infrastructure
There are no ready-made solutions for data infrastructure, but here are five areas to focus on:
- Define your data infrastructure strategy. You need to have a clear idea of where you’re going to store your data.
- Choose a repository to collect data. How do you want the information to be presented?
- Clean data and optimize data quality. Be prepared for the fact that it’s not realistic to expect to collect only clean data.
- Build an ETL pipeline. Take into consideration the constantly increasing requests for analysis of new information and make your pipeline ready not only for basic scripts but for more complicated data challenges.
- Take care of data governance. This is a key enabler of your data value.
Define your data infrastructure strategy
A concise data infrastructure strategy will save you a lot of effort in the future. First, think of where you will manage your data: in the cloud or on-premises.
The prospect of maintaining your own data center may seem unprofitable, but this is only applicable to small companies. If your organization has enough resources to contain hardware, it may even prove to be more cost-effective. In terms of reliability, there is no difference between the two options. Talk to our cloud expert to help you decide which option is better for your organization’s needs.
Choose a repository to collect data
The right data architecture is the backbone of a technically up-to-date BI platform. Here you have a choice between using a data lake or data warehouse as your available solution. So, what are the differences between them, and should you use only one of the options or explore a hybrid solution?
Sometimes a data lake is understood as a part of a Big Data infrastructure, whereas a data warehouse is shown as a repository for general data. However, it’s not that simple and they differ in many ways.
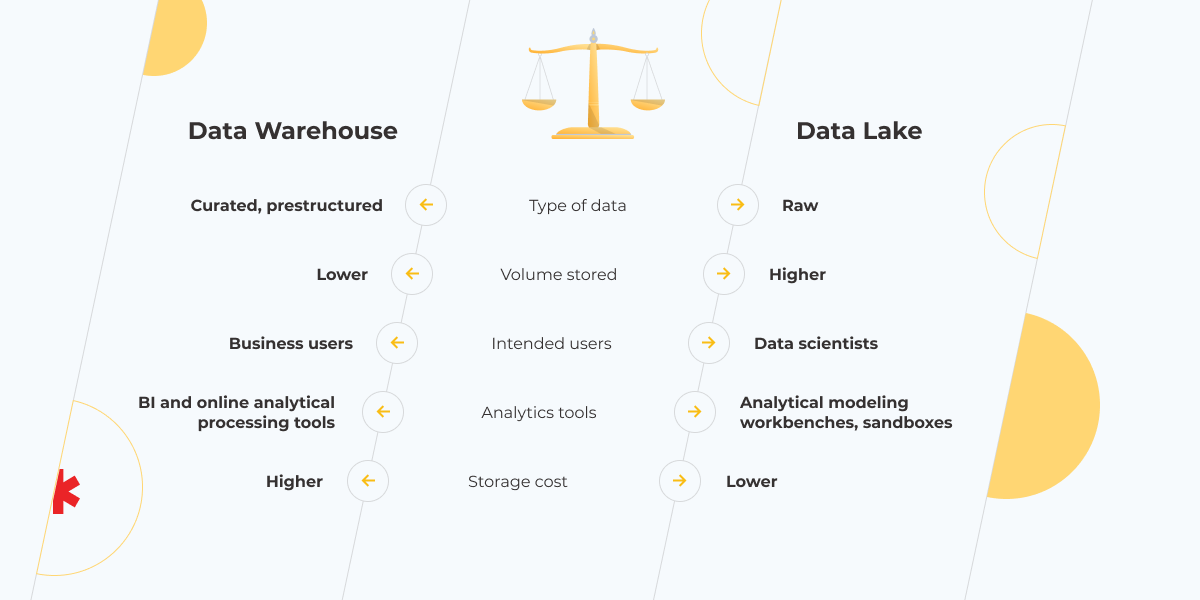
Earlier, when the amount of data wasn’t as huge as it is now, data warehouses were the definitive solution to data storage. This was because it didn’t take data engineers that much time to build a repository that met the needs of a particular business. However, when Big Data came on stage, bringing information that was exponentially growing in quantity and deteriorating quality-wise, the days of the data warehouse monopoly were doomed.
Currently, with so much data generated every day, more time and effort are required to develop a data warehouse solution. Fortunately, you have a choice: invest resources in building a data warehouse that contains structured and certainly easier to analyze data or use a data lake with simpler architecture and raw information.
Indeed, a data lake is oriented more toward big data. Here information is stored in an unstructured format but in much higher volumes. The users of such data are data scientists. This kind of repository is relatively inexpensive, so you can use your data lake not only as a storage space but also for experiments with temporary sandbox areas, where experts can build and train models for any task. It’s genuinely useful when the amount of data scales and you need to deal with it and update the data infrastructure in parallel. Often a data lake solution makes sense for information for use cases that haven’t been defined yet.
That said, this doesn’t have to be an either-or decision. There’s also the option to go for a hybrid solution. You can keep the data with minimal business meaning in a lake while storing the useful and relevant data in a warehouse; or use a data lake to collect data and a DWH to structure it. But keep in mind, that these repositories use different technologies: data lake – NoSQL, data warehouse – SQL. So you have to resolve this contradiction when deciding to build your data infrastructure.
Clean the data and optimize data quality
Problems that may arise out of inaccurate data are numerous and the departments within your organization they can affect are no less. That’s why data cleaning must be given the highest priority. To create an appropriate data cleaning process you need to take the following steps:
- Identify and delete irrelevant and duplicate datasets.
- Fix errors in the data structure.
- Come up with organization-wide rules of cleaning incoming data.
- Invest in data tools that allow you to clean data in real-time.
Last but not least — be aware of your information quality. The data must always satisfy six conditions:
- Completeness. All data sets and data items must be recorded.
- Uniqueness. This parameter is kept if data has only been registered once.
- Timelessness. This is about how useful or relevant your data is according to its age.
- Validity. The data you’ve recorded must reflect the type of data you set out to record.
- Accuracy. This metric determines whether the information you hold is correct or not.
- Consistency. You can compare data across data sets and media, if it’s all recorded in the same way.
Build an ETL (Extract, Transform and Load) pipeline
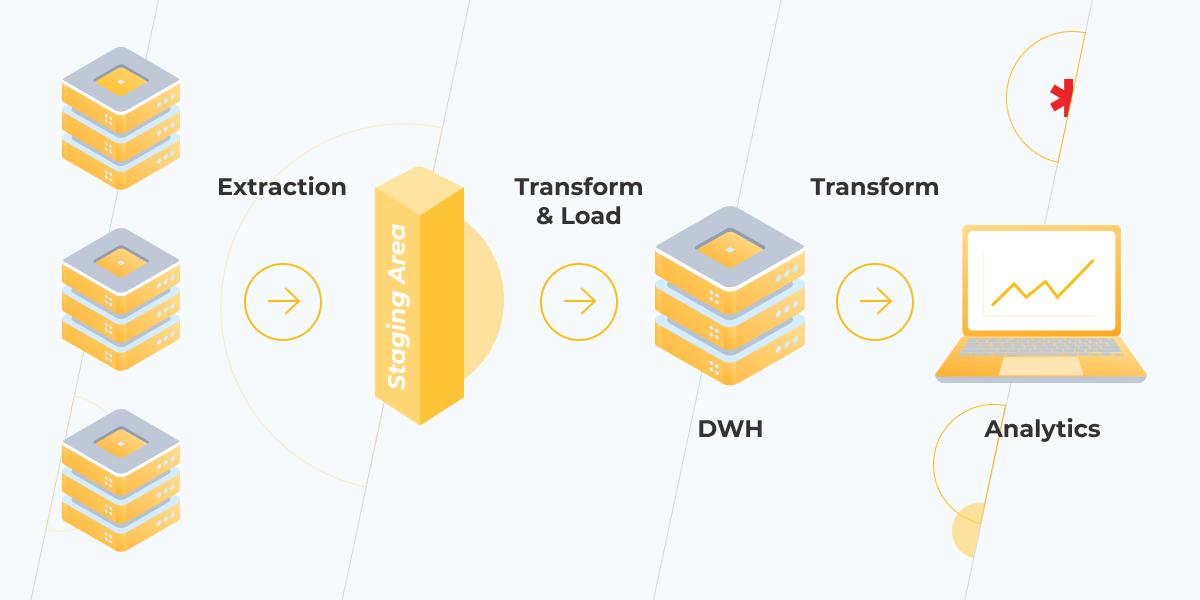
The importance of an ETL process to a company’s data warehousing and analysis, in general, can’t be overstated. A well-engineered ETL pipeline brings structure to your information as well as contributes to its clarity, completeness, quality, and velocity. However, there are a lot of challenges you might need to overcome while working on your ETL project. Here are only some of the most prevalent:
- data formats changing over time;
- broken data connections;
- contradictions between systems;
- addressing the issues of different ETL components with the same technology;
- not considering data scaling;
- failing to anticipate future data needs.
Nowadays, the data engineering space is flooded with a plethora of tools that are supposed to automate, accelerate, and take care of ETL processes for you. New technologies pop up nonstop, making the desire to switch from one tool to another almost irresistible: “Everyone’s using Spark! But, what about Apache Airflow?! Let’s try DBT!” The thing is that being on-trend doesn’t matter as much as fundamentals remain the same. So you’d better focus on getting the basics right. Tools come in second. But if you need a well-designed ETL pipeline and some advice on how to build one, our BI experts are ready to help.
Take care of data governance
All the actions above make little sense without proper data governance. It increases efficiency by giving your business a solid database to work from and saving time on correcting the existing data. Besides, it helps to avoid risks associated with dirty and unstructured data and avoid regulatory and compliance issues.
Once you are ready to embrace data governance, make sure that all the stakeholders and data owners are involved in the process and the goals you’d like to achieve are clear, specific, and measurable.
There’s actually one more thing to keep in mind during data governance implementation: it’s not a project but rather a practice that should consistently evolve and develop.
Solid data infrastructure empowers in-depth analysis
A strong data infrastructure smooths the road for data science efforts. To benefit from it, you need to care about collecting raw data, cleaning it, and making it accessible. Before you go mainstream and start analyzing your data to get perceptive insights, think about who in the organization will have access to the data, how it will be used? Structured information is more accessible and easier to interpret. A clear data infrastructure strategy is key to measurable business success.
Need some expert assistance with building a strong data infrastructure?
FAQ:
Data infrastructure is a broad concept. Just like physical infrastructure, it includes a number of components. These are data assets, servers, storage as well as processes, policies, and guides on how to manage the data.
Data infrastructure provides a solid basis for data analysis You can’t get valuable insights without suitable tools that prepare your data for analysis. Although the correlation between Data Infrastructure and business benefits is indirect, without a reliable infrastructure you can’t get the right data and properly analyze it to make it work for your business.