Contents
Impeccable data quality and accuracy are deemed vital precursors in the quest for data-driven decisions. This strategic reliance on information leaves no room for error and places input transparency at the heart of the data management process. Automated data lineage is what gives you confidence in your assets and helps eliminate any errors throughout your data flows.
Data lineage tools allow companies to look into the “what”, “when”, and “where” of their data. They give the full context to the final insights, be it the input source or the evolution cycle. Let’s see what else this data-related practice can bring to the table.
What is automated data lineage?
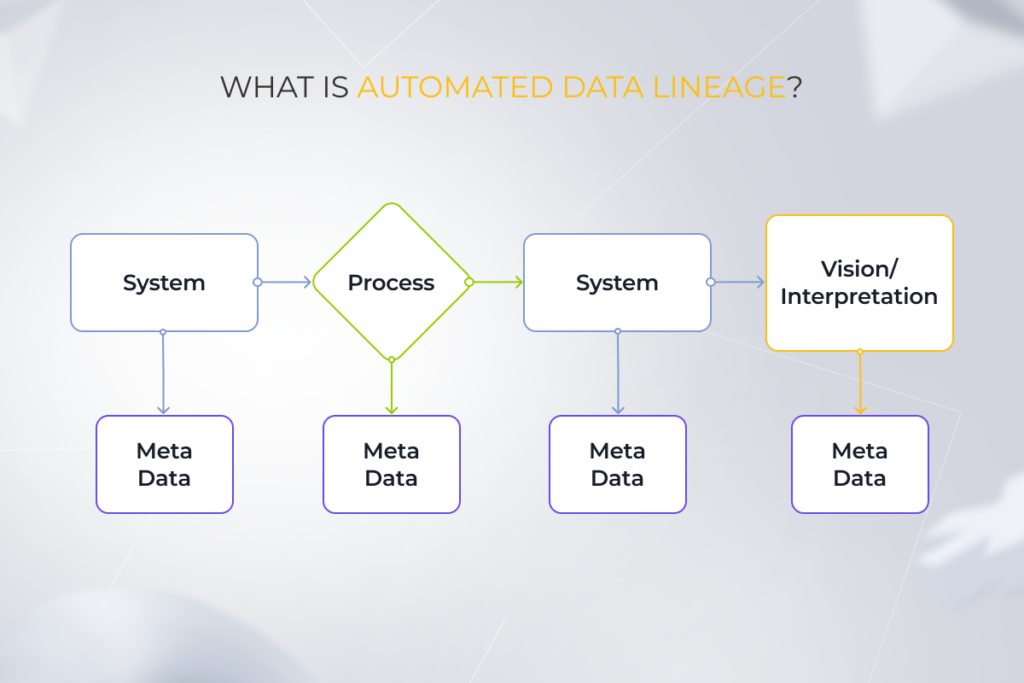
Data lineage refers to the process of tracking and visualizing data flows throughout the organization – from the source to the ultimate destination. Lineage graphs tell the story of your company’s data and demonstrate how it took its current shape, whether it’s by merging, transforming, or integrating.
Origin tracing goes hand in hand with metadata. The latter summarizes information about the data itself, including its type, format, author, date created and updated, etc.
Because of this, data lineage produces a data mapping framework by gathering metadata from each step of the pipeline. Lineage tools then store these insights in a metadata repository and demonstrate over-time changes via metadata through simple visual flows.
How can data lineage bolster your analytics?
Over 80% of companies report revenue growth after adopting real-time analytics systems and processes. But how can you get your analytics right against the odds of multiple business systems and applications? Data lineage (and not just some lineage, but an automated one) can save you a lot of effort when it comes to business analysis.
Simplify root cause analysis
It’s common for different business units to act on the same metric. However, when it comes to quarterly planning meetings, each department head suddenly reports a different number on the same KPI. Let’s take ‘sales per quarter,’ as an example. The sales department might claim that they’ve made $1m, while the finance department says it’s $0.75m, as that’s the amount of money that has been deposited into the account As a result, the persistence of erroneous data throughout the enterprise’s systems and robs decision-makers of time and productivity, as they must continuously vet data to ensure it remains accurate.
By automating data lineage, business leaders can easily trace the origin of reporting errors. The stepwise record of data assets sheds light on the black box of insight generation and builds trust in the data estate of the given organization.
In particular, up-to-date data lineage helps you locate the most upstream nodes of your system that experience the issue. Most likely, this would be ground zero for your problem. The following lineage graph visualizes the hierarchy of data within the organization.

Also, if your data and BI management are in good shape, you won’t even need the help of a BI team to trace it back. Meanwhile, mature data architectures that saw little maintenance might need a dedicated BI unit to restore the origins.
Achieve and maintain compliance
The complex data landscape makes adherence to regulations an uphill struggle for compliance-heavy organizations. Companies just cannot provide the required level of transparency needed to meet HIPAA, GDPR, and other guidelines.
Data-lineage documents help organizations map data flow pathways with Personally Identifiable Information to store and transmit it according to applicable regulations. In this case, companies can capture the entire end-to-end data lineage (including depth and granularity) for critical data elements.
Get answers as questions arise
Although pipeline mapping alone cannot ensure data accuracy, automated data lineages can at least deliver a full view of the metadata so that you can see why exactly you have this number in your report. Put simply; you can locate a given business term and trace it to multiple applications, data sources, models, analytics, and other elements of your digital estate.
Unlike manual data tracing, automated data lineage tools minimize errors and return the result in seconds with each manipulation logged.
Simplify data migration
Data integrity and quality issues tend to haunt the majority of migration projects. According to the study, 44% of U.S. organizations admit that poor data quality slows down the migration process. Moreover, unless eliminated, these issues can affect downstream systems and manifest themselves when it comes to the end user. Also, these are tricky to spot during data testing.
To tackle migration challenges, data engineers need to identify the location and lifecycle of data sources. By using automated data lineage, your data migration team can obtain this information flat out, minimizing migration risks. Your engineers can leave all duplicate, outdated, and redundant data behind and identify the structure of a data asset slated for migration.
Instant impact analysis
To estimate the scale of data change, tech specialists resort to impact analysis that demonstrates which downstream systems will be affected in the process. Automated lineage helps pinpoint dependencies and identify the exact stages under impact – with little to no manual effort. Those stages can then be revised to accommodate the changes and promote data consistency across systems.
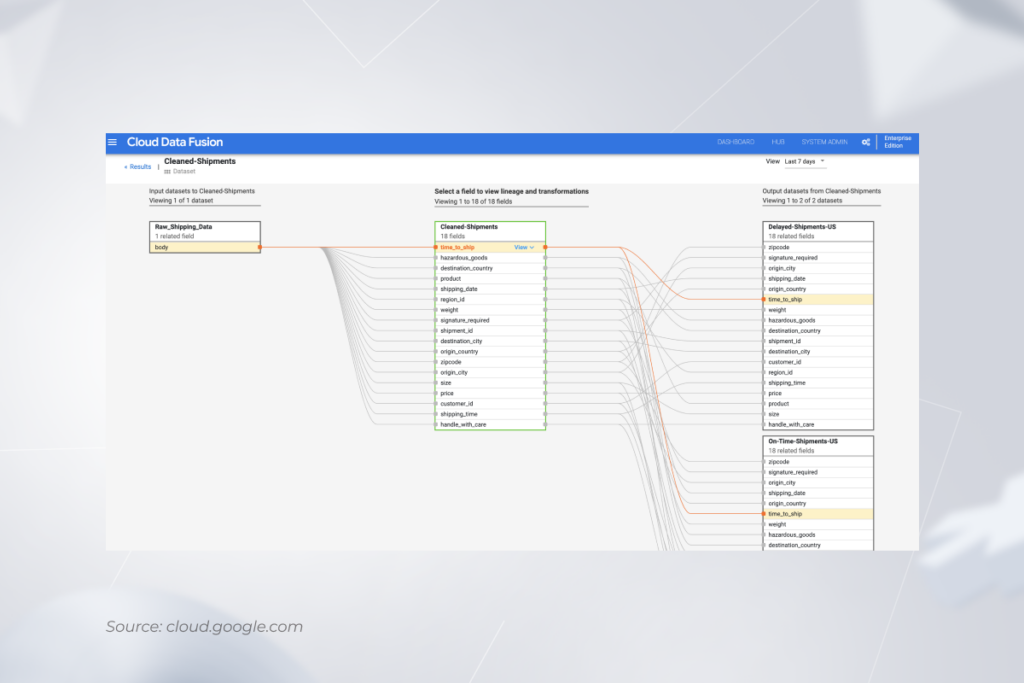
The following data lineage diagram example demonstrates how data flows through four different applications:

This is why if you introduce changes to your data warehouse, you can easily see which dashboards the alterations will impact.
Leverage the power of data lineage for analytics
Manual vs. automated data lineage: which does it better?
When it comes to origin tracing, companies and their IT departments have two options. They can either delegate this task to automated data lineage tools or rely on manual, also known as descriptive, data lineage.
Descriptive data lineage
A descriptive data lineage is one documented manually. In this case, data analysts dedicate effort to recording the information about how the data element is updated over time and how it ends up in a warehouse. This type of lineage is extremely time-consuming and prone to errors stemming from manual input.
Automated data lineage
By delegating lineage to a tool, you automatically handle the metadata recording process. Automated tools trace the asset changes and transformations throughout its lifecycle and make that information readily available via visualizations. From a tech standpoint, you provide meta-integration components to the tool and can then access the visualizations even with no prior knowledge of ETL processes.
However, data lineage automation calls for careful scope selection as this initiative can turn out quite expensive with the wrong choices. Also, the more legacy systems you have, the more data lineage challenges you will face, as aging ecosystems cannot provide metadata sources.
Tracing automation allows you to reduce the expense and effort required to document data lineage. Tools offer autodiscovery and integrations based on machine-learning techniques for creating metadata and building interactive data-lineage flows. Conversely, manual tracing has its inherent challenges linked with resource intensity and isolated workflows as it sits within the remit of the data governance team.
Сommercial or open source data lineage tools: which one to choose?
Data is a man of a thousand faces. And it’s either canned solutions or open-source data lineage tools that can reveal the true face of your assets. Let’s have a closer look at the dichotomy between the two.
Costs
Although it’s impossible to put an accurate price tag on both, making your data lineage open source appears to have more cost-saving potential, at least at first sight. However, free lineage tools typically cannot suffice your unique business needs, thus requiring pricey customizations to an indefinite extent. Commercial tools have all pricing options laid out for you.
Ease of use
Open-source data lineage tools usually require more time and effort from users to navigate due to complex user interfaces and little onboarding guidance. Contrarily, commercial tools tend to walk the user through the interface with more intuitive flows, solid documentation support, and managed pathways.
Alignment with your architecture
If your tech ecosystem already revolves around a particular provider, such as Microsoft Azure, it’s only logical to choose a lineage tool from the same supplier. In this case, the tool will integrate natively into your ecosystem and have no compatibility issues. However, if your stack isn’t centered around a specific offering or you don’t want to go big with your lineage efforts, you can opt for open-source tracing.
For example, one of our clients has a well-calibrated data management process where the team has almost complete visibility into how the data circulates between the systems. The client’s team injects lineage graphs only when they need to dig deep into the data. In this case, open-source tools will be enough.
Integrations and scope of visualizations
As lineage involves tracing the data footprint throughout its entire journey, data lineage tools should be able to integrate easily with your current stack. This includes everything from storage, injection, and visualization and all other stages where your data is originated, stored, or transformed.
Commercial software usually takes over the whole data lifecycle, thus having access to all processing stages via proprietary APIs. As a result, canned software visualizes detailed, all-encompassing insights about your data lineage.
For example, data lineage in Power BI integrates natively with the entire Azure ecosystem, while open-source software requires you to build custom APIs to access metadata.
Struggling to choose the right lineage tool?
Adopting data lineage: best practices
The main rule of thumb in implementing lineage is to balance this practice against your unique needs and existing capacities. For example, in some cases, the project agenda of our clients requires our data engineers to resort to dedicated lineage tools such as Monte Carlo. In other cases, we build and connect this feature on top of other tools like Apache Airflow.
While lineage experience varies by company, we still have some universal advice on how to track your data origins in the most holistic and comprehensive way.
Keep it omnipresent
To remain authoritative, data lineage should permeate each stage of your data journey, including the phases of sourcing, ingesting, storing, analyzing, and visualizing. However, its presence at each stage should be meaningful and insight-rich, contributing unique nuggets of information to the knowledge body. So when deciding on the integrations, make sure you map data elements at every stage.
Prioritize quality over quantity
Over the last few years, there has been a dramatic shift from vast reams of data to knowledge centered around individual data components. The same trend applies to lineage automation. Instead of embracing the entire data landscape, it’s better to look into relevant metadata details, such as the asset owner and the presence of the asset in downstream sources. This way, you can define the value of each asset for your analysis.
Have the lineage view at the field level
Field-level lineage is key to understanding the relationship between the fields in the data set, thus facilitating root cause analysis. When your pipeline cracks, field-level lineage automation allows your data teams to see exactly how each field of your data circulates in your system and which transformation it has been subject to.
Keeping it at the field level helps to ensure the accuracy and quality of insights, point out errors in a revenue report, and trace columns with sensitive information to downstream dashboards.
Decide on the unified data lineage language
Just like any business communication, data lineage should be based on the common dictionary of terms to spread knowledge within the company. To establish a common understanding, your data lineage should rely on clear naming, which represents the data it’s describing. Naming conventions and style guides help people analyze data consistently, making data lineage diagrams easily digestible for all team members.
You can also streamline communication about data lineage between multiple stakeholders to maintain a shared understanding and get feedback on your graphs. To do that, your lineage tools should include built-in collaboration capabilities and notify asset owners about data changes.
Collect, store and prioritize metadata
While troves of high-level data hardly translate into accurate data lineage graphs, substantial amounts of metadata are beneficial to your tracing efforts. Therefore, having a rich metadata repository leads to a more comprehensive snapshot of all report components and faster troubleshooting. Also, including the relevant metadata for a given data asset makes your lineage graph exhaustive and helps you fully realize how potential changes will turn out in reports.
Let data lineage grow with your business
As your business expands, the data footprint of your business processes also builds up. To maintain data tracing complete and full coverage, your lineage architecture should be scalable and include an ever-evolving input stretch. This is why, no matter the analysis area, your lineage tool should look into every pipeline, report, and stack layer at the field level, joined by ample metadata.
Solving the mystery of data discrepancies
Knowing what goes into your report gives you confidence in your data and guarantees the right course of action afterward. Automated data lineage helps you develop a full view of your data evolution and track an individual number to its place of origin, preventing errors in decision-making. However, getting an accurate lineage graph requires a well-balanced data architecture to let the lineage tool mine metadata throughout the entire data lifecycle.
On the journey to better data quality?