Updated: May 29, 2026
Contents
Does size still matter? With AI, the default assumption used to be “yes.” More parameters, better results, end of story. That logic held until small language models (SLMs) started punching above their weight. Gartner’s prediction is that smaller, task-specific models will hit 3× the deployment volume of general-purpose LLMs by 2027, a signal that the LLM vs. SLM question has shapeshifted. Business owners who once asked “which model should I pick?” are now asking how to orchestrate both.
Instinctools’ AI engineers have mapped the SLM vs. LLM comparison as it stands today, underlining when it’s reasonable to downsize to an SLM, and when banking on an LLM pays off.
What is an LLM and what is an SLM?
Both large and small language models (LLMs and SLMs) are artificial neural networks trained on vast amounts of data and built to process and understand natural language and perform a range of tasks from simple text summarization to taking actions on the user’s behalf.
If all language models rest on the same foundation, what is the difference between LLMs and SLMs? Primarily, the number of parameters, which are the internal values a model learns during training. The more parameters it has, the more patterns it can usually capture. SLMs typically range from 1 billion to 15 billion. Phi-4-mini, Mistral 7B, and DistilBERT are some of the go-to picks in this range. LLMs start in the tens of billions and reach into the trillions, with GPT, Claude, and Gemini models leading the pack.
LLM vs. SLM: key differences at a glance
The SLM vs. LLM gap no longer boils down to “small versus powerful.” The tradeoffs stretch across infrastructure costs, latency, deployment flexibility, reasoning depth, and governance overhead. Here’s how both model families compare in production environments.
| Criteria | SLM | LLM |
| Resource requirements | Runs on consumer hardware, edge devices, or a single GPU | Requires high-end GPU infrastructure and large memory footprint |
| Cost of adoption and usage | Lower inference costs, but usually requires fine-tuning | Higher inference costs, though broader out-of-the-box capabilities reduce customization work |
| Fine-tuning time | Hours to weeks with LoRA/QLoRA on limited hardware | Months (in rare cases when fine-tuning is necessary) |
| National specificity | Diverse representation of alphabet-specific languages | Broader multilingual coverage, but uneven cultural representation |
| Capabilities range | Strong in narrow, repetitive, and latency-sensitive tasks | Better at broad reasoning, orchestration, and open-ended workflows |
| Inference speed | Faster response times and lower latency | Slower inference, though MoE architectures narrow the gap |
| Output quality | Lower due to a smaller context window | More reliable in complex reasoning and long-context tasks |
| Security | Might present certain risks (API violation, prompt injection, training data poisoning, confidential data leakage, etc.) and requires clear AI governance | |
Advantages of SLMs over LLMs
SLMs have earned their spot as a practical alternative to large language models for businesses that want to adopt AI without investing a fortune into the technology. The core advantages of an SLM over an LLM include:
- Lower inference cost (up to 100 times cheaper per query via API, and zero per query when deployed on-device).
- Faster response times, especially for short, bounded tasks such as classification, routing, extraction, autocomplete, simple customer support, and local assistants.
- Reduced vendor lock-in when using open-weight models, as businesses can self-host, fine-tune, quantize, and move models across different infrastructure stacks.
- Deployable on consumer hardware, edge devices, and smartphones, particularly with quantized models such as Llama 3.2 1B/3B, Phi, and Gemma-family models.
- Faster and cheaper customization (weeks and a single GPU vs. months and a cluster).
- Lower energy consumption per inference, a smaller carbon footprint at scale.
When LLMs still win: strengths of large language models
LLMs are broad-spectrum AI language models built for complex tasks that require broad knowledge, multi-step reasoning, and deep contextual understanding. The LLM advantages over their smaller counterparts include:
- Stronger multi-step reasoning across domains like legal analysis, financial modeling, and scientific research.
- Much larger context windows, enabling the model to work with long documents, large research corpora, complex conversations, and sometimes substantial portions of codebases or document sets in one pass .
- Multimodal capabilities covering text, image, audio, and video in a single model.
- Lower need for task-specific fine-tuning, because frontier LLMs often perform well with prompting, retrieval-augmented generation, tools, and examples. However, production deployments still require evaluation, guardrails, monitoring, and workflow design.
- The reasoning and planning depth that makes LLMs a natural fit for the orchestrator role in multi-agent systems, where a central model coordinates and routes tasks to specialized smaller models.
An SLM vs LLM comparison across 8 criteria
Building and training models from scratch requires significant investments, often beyond the reach of many businesses. That’s why, in this article, we focus exclusively on pre-trained models, comparing notable LLMs such as ChatGPT, Claude, and Gemini, with SLMs like Mistral, Phi, and Gemma.
1, Resource requirements
When it comes to SLM vs LLM resource requirements, the gap remains wide. LLMs contain hundreds of billions to trillions of parameters, and high memory consumption makes them a resource-intensive technology. If you target the latest GPT, Claude, or Gemini models, you’ll need NVIDIA H100 or B200 GPUs, which cost $25,000-$35,000 per processor.
SLMs’ compact model size and lower computational power requirements enable them to run on a broader range of devices, including regular computers and smartphones. For instance, Microsoft’s Phi-4-mini needs just 4GB of RAM, so with an SLM as a resource-friendly alternative to LLM, companies can hop on the AI train without upgrading their hardware park.
Instinctools’ verdict: SLM.
2. Cost of adoption and usage
The cost coin has two sides: fine-tuning and inference. LLMs save on fine-tuning since they handle most tasks out of the box, but inference adds up quickly at scale. SLMs need fine-tuning, yet their day-to-day usage is far more affordable.
To feel the disparity, consider this scenario: you have 300 employees, each making five small 1K-token requests per day. At the time of writing, a frontier GPT model priced$1.75/$14.00 per 1M tokens, that adds up to around $720/month. Replace it with Gemini Flash at $0.10/$0.40 per 1M tokens, and the same workload drops to roughly $22.50/month.
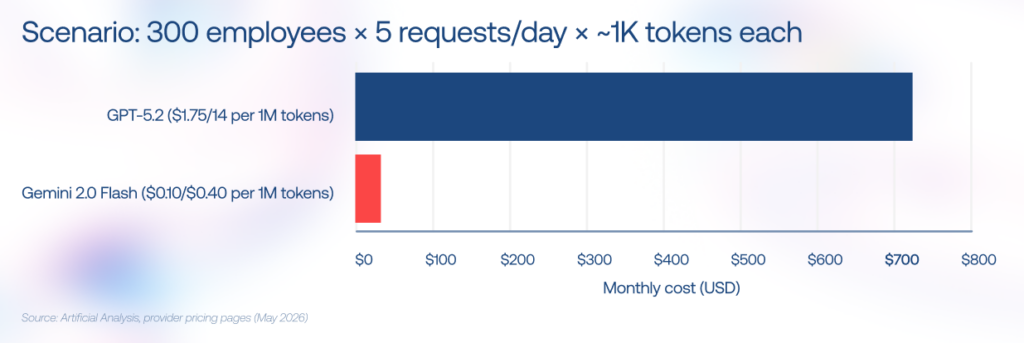
Instinctools’ verdict: SLM.
3. Fine-tuning time
The logic behind the fine-tuning process is straightforward: the more parameters the model has, the longer it takes to calibrate it. In this regard, adjusting a large language model with trillions of parameters can take months, while fine-tuning an SLM can be completed in weeks.
Parameter-efficient methods like LoRA and QLoRA have shortened the process further. A 7B model can now be fine-tuned on a single GPU in hours, which is how our team compressed a full project with Mistral 7B at its core into just six weeks, stepping up the model’s precision rate from 10% to 75%.
Instinctools’ verdict: SLM.
4. National specificity
The lion’s share of the most well-known LLMs originates from the US and China and doesn’t adequately represent diverse languages and cultures. Studies unveil that LLMs’ outputs skew toward WEIRD societies (Western, Educated, Industrialized, Rich, and Democratic).
Sovereign AI has become a trend, with governments commissioning models trained on local-language datasets. If you compare small language models and LLMs on language coverage, SLMs lead the push with Jais for Arabic, Nanda for Hindi, Typhoon for Thai, and Viking for the Nordic languages.
Instinctools’ verdict: SLM.
5. Capabilities range
Both LLMs and SLMs emulate human intelligence but at different levels. LLMs remain the go-to for complex tasks requiring broad knowledge, multi-step reasoning, and deep contextual understanding. Once you move to multi-agent systems, LLMs carry the orchestration work, coordinating several agents, tracking long-horizon objectives, switching tools mid-process, and resolving conflicts between intermediate outputs.
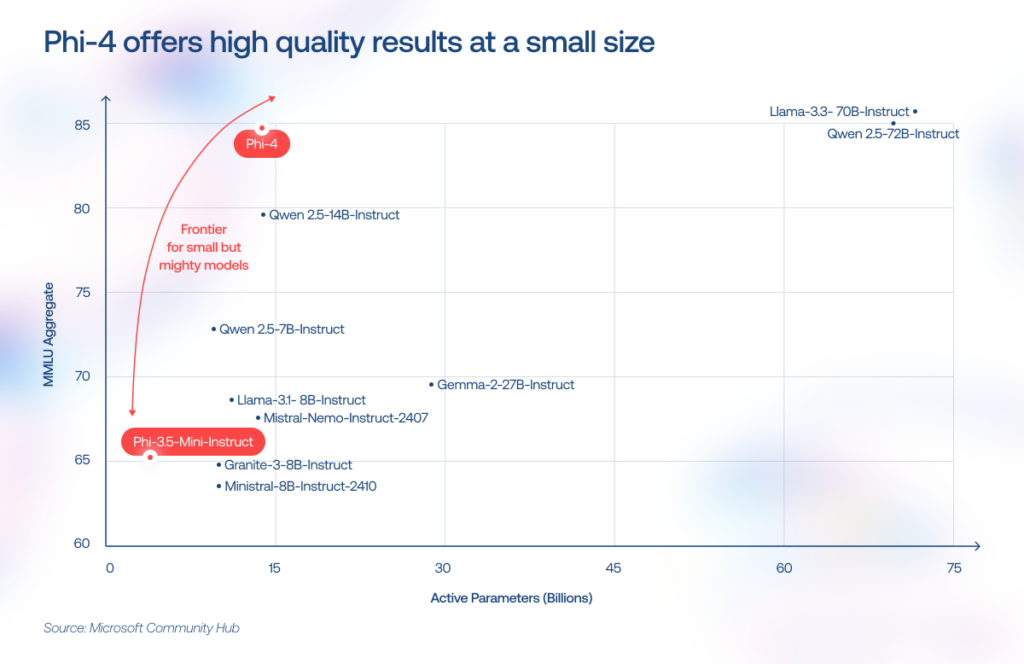
SLMs are narrow-focused models designed for specific tasks like text classification, summarization, and entity extraction. But the gap is narrowing. For example, Phi-4-mini (3.8B parameters) now matches models twice its size on reasoning benchmarks, a gap that would have been unthinkable two years ago. SLMs have also gained 128K context windows, function calling, and vision capabilities. So with strong context engineering, you can squeeze far more out of a compact model than raw parameter counts would suggest.
What we witness on the ground is that enterprise AI stacks now resemble a relay race, when an LLM acts as the planner and coordinator and passes the baton to lightweight SLMs to handle specialized subtasks at lower cost and latency.
— Pavel Klapatsiuk, AI Lead Engineer, Instinctools
Instinctools’ verdict: LLMs and SLMs to get the best of both worlds.
6. Inference speed
LLMs’ power as a broad-spectrum solution comes with performance trade-offs. In dense architectures, more parameters typically mean more computation per generated token, which can make large models slower and more expensive to serve than smaller models.
LLM providers address this by switching from dense architectures to sparse Mixture of Experts (MoE) patterns and by releasing their own lightweight tiers (GPT-5 nano, Gemini Flash). On the SLM side, Mistral Small 3 runs at 143 tokens/second on 16GB of RAM, and Gemma 4 (a 26B MoE model) also targets faster local inference with techniques such as multi-token prediction.
For latency-sensitive SLM vs LLM decisions, smaller models often have the edge, especially for short, repetitive, on-device, or edge workloads.
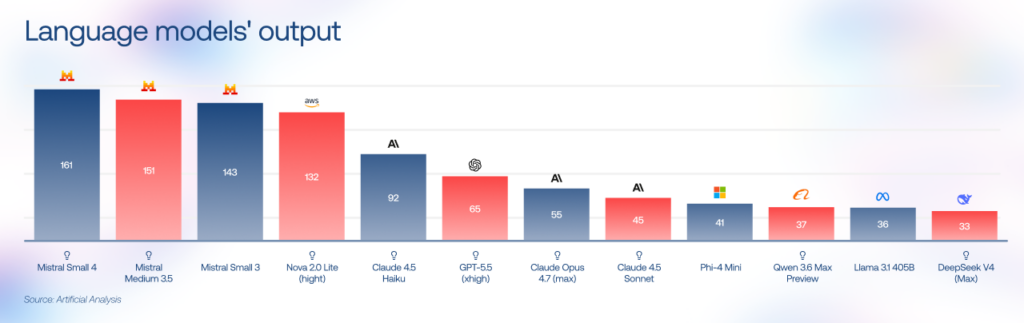
Instinctools’ verdict: SLM.
7. Output quality
On general reasoning and coding benchmarks such as MMLU-Pro, GPQA, SWE-bench, LiveCodeBench, HumanEval, and MMMU, frontier LLMs outperform smaller models, especially in open-ended reasoning, advanced coding, and multilingual tasks. Their advantage comes not only from broader training data, but also from greater model capacity, stronger post-training, reasoning-focused optimization, tool use, and more mature long-context handling.
SLMs can achieve comparable accuracy on narrow enterprise tasks when the workflow is well-defined and supported by high-quality domain data, retrieval, prompt engineering, constrained outputs, or fine-tuning. But once the task moves beyond a tightly controlled scope, larger models tend to stay more stable and coherent under pressure.
Instinctools’ verdict: LLM.
8. Security
While the cost and quality of AI solutions often make enterprise leaders scratch their heads, it’s the security concerns that really top the list of hurdles. Any production AI system needs clear governance around what data enters the model, where that data is processed, how long it is retained, who can access it, and how model outputs are logged, monitored, and audited.
For cloud-hosted LLMs, organizations should evaluate vendor terms, data-retention policies, training-data exclusions, API access controls, encryption, logging, data residency, and regulatory compliance before deployment. Many enterprise AI providers now offer strong privacy commitments (for example, API or enterprise customer data is commonly excluded from model training by default), but companies still should validate these guarantees against their own security, legal, and compliance requirements.
SLMs need robust governance just as much, but they give companies far more flexibility in where data gets processed and stored. Small models can run on-premises, on edge infrastructure, or directly on employee devices, giving businesses tighter control over where sensitive information is processed and stored. This setup is particularly attractive for industries handling regulated or proprietary data.
Instinctools’ verdict: SLM.
When to choose an SLM vs. an LLM: decision framework
Choosing the best AI models in the SLM vs. LLM debate is like hiring a team. You don’t bring in a Nobel-level strategist to sort invoices, and you don’t hand a billion-dollar negotiation to an intern fresh out of onboarding. AI stacks work the same way, routing simple jobs to smaller models and reserving heavyweight reasoning for the few tasks that need it.
| Use case | Recommended model type | Why | Example models |
| Customer support chatbot | SLM | High request volume, predictable workflows, low latency requirements | Mistral Small 3, Phi-4-mini |
| Internal document Q&A | SLM | Easier on-prem deployment and domain fine-tuning | Llama 3.3 8B, Gemma 3 |
| Code copilot | LLM or hybrid setup | Multi-file reasoning and long-context understanding | Claude Sonnet 4.6, GPT-5.2 |
| Edge or IoT device | SLM | Minimal compute footprint and offline operation | Llama 3.2 1B, Gemma 3n |
| Healthcare records processing | SLM | Greater control over sensitive data handling | Fine-tuned Mistral, Phi-4 |
| Multilingual content generation | LLM or sovereign SLM | Broad language coverage versus local cultural adaptation | Gemini 3.1 Pro, Qwen 3 |
| Creative or long-form writing | LLM | Better narrative consistency and contextual depth | Claude Opus 4.6, GPT-5.2 |
| Multi-agent enterprise workflows | Both | Balances cost, speed, and reasoning quality across tasks | SLM workers + LLM orchestrator |
Frontier LLM, compact SLM, or a hybrid setup?
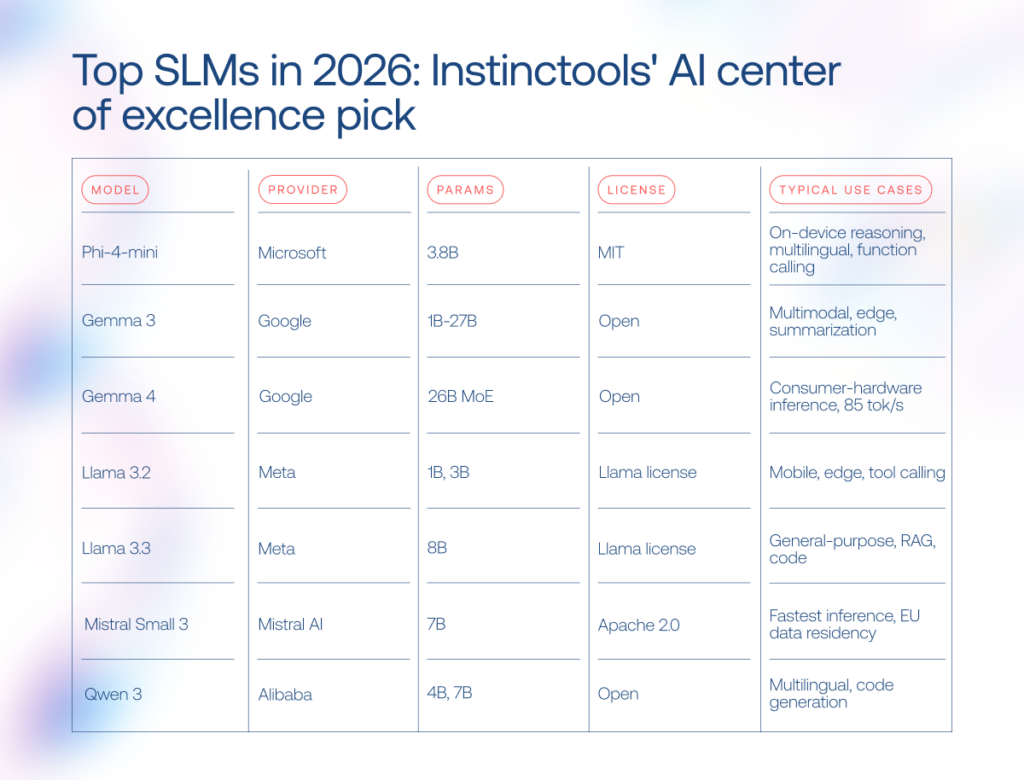
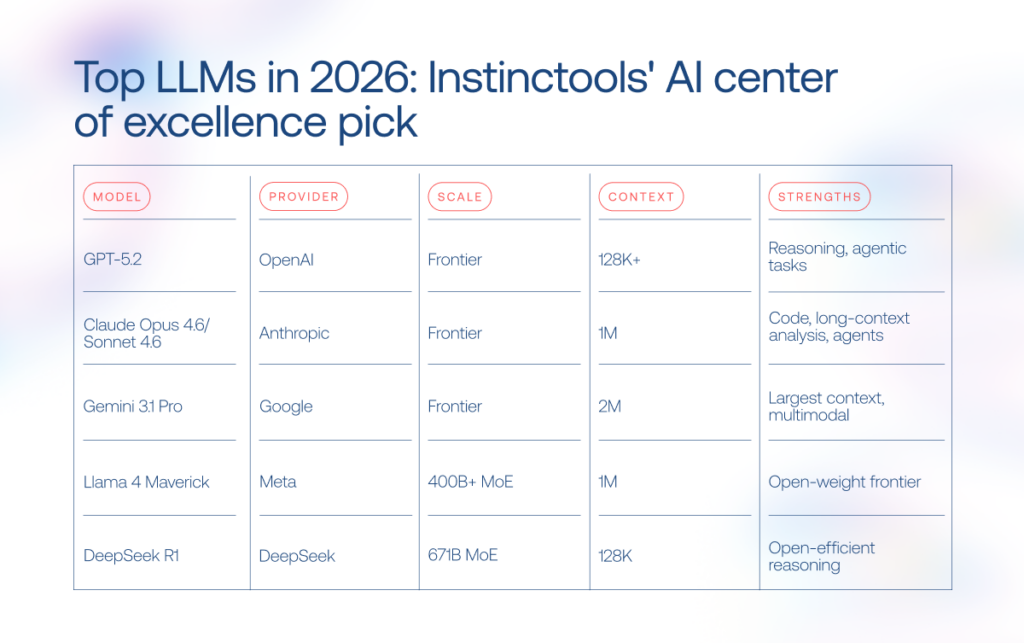
Examples of SLMs and LLMs in production for 2026
The AI language model market has become crowded fast. A couple of years ago, most discussions revolved around GPT-4-level systems. Now the field stretches from billion-parameter SLMs running on laptops to LLMs built for multi-agent reasoning and million-token context windows.
Custom LLM and SLM development with Instinctools
Now that you know where SLMs make sense and where LLMs still dominate, the harder part begins: turning that knowledge into an AI system that survives contact with real production workloads.
Our team helps businesses with custom LLM/SLM development, covering:
- Model selection based on your business requirements and limitations
- Fine-tuning on private data
- RAG pipeline integration
- Goal-oriented context engineering to widen the range of AI capabilities
- Agentic workflow design and orchestration
- MLOps
- Fully on-premises deployments
Sometimes the answer is a compact SLM running locally for privacy and latency reasons. Sometimes it’s a tiered architecture combining multiple models behind one orchestration layer.
Our AI engineers are a click away if you need expert advice
The future belongs to hybrid AI stacks
After exploring what’s possible, determine what’s practical for your software needs. Both LLMs and SLMs are powerful tools, but they won’t bring the desired benefits on their own. It’s still essential to identify how to effectively integrate them into your business processes, considering industry and national specifics.
If your resources are limited, you want to test your idea ASAP, or need a model for only a specific type of task, an SLM can help you hit it big without breaking the bank. For deeper reasoning, multi-agent orchestration, or long-context analysis, LLMs hold the advantage. In practice, though, the biggest gains come from combining both: smaller models handling high-volume routine work, larger ones stepping in for the hardest decisions.
Draw on the power of language models with a trusted tech partner
FAQ
The difference between an LLM and an SLM comes down to scale, training scope, and intended use. LLMs are trained on massive web-scale datasets and usually contain tens or hundreds of billions of parameters, making them better suited for broad reasoning and open-ended tasks. SLMs are smaller, often below 10B parameters, and optimized for focused workloads like classification, summarization, or on-device AI. For example, GPT-5.2 is built for broad reasoning, while Phi-4-mini (3.8B) is designed for efficient local inference. Still, the boundary is getting blurrier with each new model.
The biggest advantages of SLMs over LLMs are lower cost, faster inference, and easier deployment. Smaller models can run 10-50× cheaper than large-scale LLMs. They can also work fully on-premises or on edge devices, keeping sensitive data inside the company infrastructure. In narrow enterprise tasks, a well-trained SLM may also produce fewer hallucinations because its scope stays tightly controlled.
In the SLM vs. LLM standoff, SLMs make more sense when the task is narrow, repetitive, latency-sensitive, or privacy-critical. Common examples include entity extraction, summarization, customer-support routing, and edge AI systems. They also fit workloads with very high query volume, where large-model API costs spiral quickly. If your data cannot leave the company perimeter or the model needs to run locally on limited hardware, an SLM or hybrid setup is the safer bet.
Popular SLM examples in 2026 include Phi-4-mini (3.8B), Gemma 3, Mistral Small 3, Llama 3.2 1B/3B, TinyLlama 1.1B, and Apple OpenELM. Some focus on multilingual reasoning, others on edge deployment or fast inference on consumer hardware.
SLM vs. LLM output quality depends heavily on the task. On broad reasoning benchmarks like MMLU or HellaSwag, larger models still outperform smaller ones, especially when the task requires open-ended reasoning, advanced coding, multilingual understanding, or cross-domain synthesis. But in narrow enterprise workflows, the gap can shrink dramatically after fine-tuning. A well-scoped SLM processing medical records or support tickets, bolstered by high-quality domain data, retrieval, constrained outputs, or fine-tuning can match and sometimes outperform a general-purpose LLM.
The cost of custom LLM/SLM development varies mostly with data quality, infrastructure demands, and deployment complexity. Fine-tuning an open-source SLM like Mistral 7B or Phi-4 on private data usually starts around $15,000. Building a domain-specific model from scratch can reach $80,000-$250,000 or more. A production-grade RAG pipeline around an existing model often falls somewhere in between. If you want a realistic estimate, it’s worth discussing your use case with your AI engineering partner before locking into one architecture.
Yes. One of the main reasons companies adopt SLM on-premises setups is that compact models run comfortably on consumer hardware. Models below 7B parameters can work on a single RTX 4090 or even on CPUs with quantization. Lightweight options like Phi-4-mini or Llama 3.2 1B already run on laptops and smartphones. Common deployment tools include Ollama, llama.cpp, MLX, ONNX Runtime, and NVIDIA Triton.